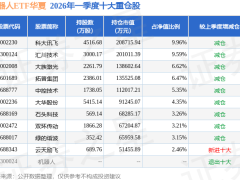
當全球AI大模型廠商還在比拼GPU數量時,中國團隊已悄然開辟新戰場——通過重構網絡架構,在未增加任何硬件成本的情況下,將推理集群算力提升15%。智譜聯合清華大學、馭馴網絡研發的ZCube架構,在GLM-5.1生產集群中實現突破性驗證,這項發表于ACM SIGCOMM 2025的成果,被國際學術界評價為"將重塑網絡設計范式"。
傳統數據中心沿用二十年的Fat-Tree/Clos架構,在應對大模型推理時暴露致命缺陷。當32卡集群將網絡帶寬從100Gbps升級至200Gbps,推理吞吐提升19%的同時,首Token時延下降22%——這組智譜實測數據揭示殘酷現實:GPU性能天花板正被網絡擁塞鎖死。在PD分離部署場景中,Prefill與Decode節點間動態不對稱的數據流,使傳統架構的熱點堆積問題愈發突出,萬卡集群中甚至出現30%的GPU因等待數據傳輸而閑置。
ZCube架構的顛覆性在于徹底重構拓撲邏輯。其核心設計原則確保任意兩張GPU間僅存在一條最優路徑,通過消除多路徑選路沖突,從架構層面將結構性擁塞概率降低80%。更關鍵的是2跳網絡直徑設計——既突破單層組網的規模限制,又避免傳統二層架構的延遲累積。這種"專屬路網"模式使千卡集群的推理吞吐提升15%,TTFT P99延遲下降40.6%,同時削減三分之一交換機與光模塊成本。在萬卡規模下,僅光網絡硬件即可節省2.1-6.4億元。
這場架構革命帶來的連鎖反應正在重塑產業鏈。當OpenAI聯合NVIDIA等巨頭推出MRC多路徑協議時,兩種技術路線形成有趣互補:MRC通過智能調度優化"交通規則",ZCube則通過拓撲重構預防"道路擁堵"。這種差異使以太網加速取代InfiniBand成為主流選擇——Dell'Oro數據顯示,2025年AI后端網絡中以太網份額已超60%,800G光模塊需求隨之激增。
在智譜的千卡生產集群中,ZCube改造涉及重新設計布線模式、IP編址和路由策略等復雜工程。馭馴網絡開發的自動化工具包,使原本需要數月的改造工程壓縮至兩周內完成。這種"零代碼修改"的升級模式,為存量AI基礎設施提供了立竿見影的優化路徑。當行業開始重新評估算力價值時,ZCube證明:通過系統級創新挖掘現有硬件潛力,其經濟效益不亞于新增GPU投入。
隨著推理集群向十萬卡規模演進,網絡瓶頸正呈現指數級放大趨勢。ZCube架構展現的擴展性令人矚目:單層Leaf交換機即可支持16384塊400G網卡互聯,若采用更高密度交換機,理論可連接數十萬GPU。這種"扁平化"設計使規模效應產生質變——集群越大,省下的交換機和光模塊成本越多,性能優勢越顯著。當AI競爭進入深水區,網絡架構正在從底層支撐轉變為核心生產力,這場靜悄悄的革命或將重新定義算力競賽規則。