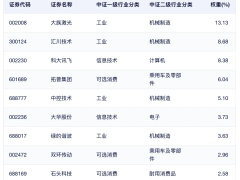
在多模態大模型(MLLM)的后訓練領域,一種長期被視為標準流程的范式正受到挑戰。傳統做法是先進行監督微調(SFT),再通過強化學習(RL)優化模型性能,這種兩步走的策略被眾多研究團隊采用,從DeepSeek到Qwen系列模型均遵循此道。然而最新研究顯示,這種看似合理的流程可能隱藏著重大缺陷——SFT階段不僅未能為后續RL訓練奠定基礎,反而可能造成模型能力退化。
實驗數據揭示了令人意外的事實:在7個主流多模態基準測試中,經過SFT訓練的Qwen3-VL-4B模型準確率從59.7%降至56.8%,8B版本更從63.3%暴跌至58.1%。這種性能下滑現象在強基座模型上尤為明顯,當SFT數據引入與原始訓練分布不同的新數據時,模型會因被迫適應更狹窄的分布模式而丟失原有能力。研究人員指出,這相當于RL訓練從"負起點"開始,后續優化過程實際上是在彌補SFT造成的損失而非真正提升能力。
問題根源在于SFT階段存在的雙重偏差機制。首先,基于token級損失的優化方式將推理過程與最終結果同等對待,導致模型學會模仿表面模式而非真正掌握推理邏輯。其次,多模態場景特有的感知-推理耦合問題加劇了訓練難度——視覺定位錯誤(感知漂移)與邏輯推導失誤(推理漂移)被同一損失函數處理,使得模型同時出現"看不準"和"想不對"的雙重缺陷。現有RL算法雖在采樣效率等方面持續改進,卻始終未能解決SFT遺留的分布偏差問題。
針對這些挑戰,研究團隊提出了創新性的三階段訓練框架:在傳統SFT與RL之間插入分布對齊階段。該方案的核心是混合專家判別器(MoE Discriminator),通過解耦感知與推理評估機制,分別用視覺專家(D_v)和推理專家(D_r)處理不同類型的偏差。這種設計允許模型同時接收關于視覺描述準確性和邏輯一致性的雙重反饋,其判別得分由兩者加權組合而成:r(x,y) = α·D_v(x,c) + (1-α)·D_r(x,t)。
該框架的另一突破在于實現黑盒蒸餾,無需訪問教師模型的內部參數。通過采集強模型(如Gemini 3 Flash)的輸出作為正樣本,結合當前策略生成的負樣本進行對抗訓練,即可完成分布對齊。這種設計極大提升了方法的實用性,使得研究者僅需調用API就能完成模型優化。實驗表明,去除傳統RL中常用的KL正則化約束后,模型在分布對齊階段的表現反而顯著提升,驗證了該設計能有效糾正SFT造成的偏差。
在Qwen3-VL模型的實證研究中,新框架展現出顯著優勢。搭配GRPO/DAPO/GSPO等主流RL算法時,8B模型在數學推理和通用視覺任務上平均提升6.0個百分點,4B模型提升4.4個百分點。消融實驗進一步證實,分布對齊階段貢獻了約40%的性能增益,而混合專家判別器的設計比單一判別器效果提升近30%。特別值得注意的是,當移除視覺感知判別器時,模型會陷入"鸚鵡學舌"式對齊,僅能模仿輸出格式而無法理解視覺內容,這從反面證明了多模態解耦評估的重要性。