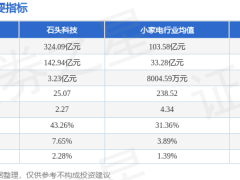
全球人工智能領域權威評測平臺Code Arena近日公布最新榜單,阿里巴巴自主研發的旗艦大模型Qwen3.7-Max以1541分的成績躋身全球前列。該模型在編程能力專項評估中位列第四,緊隨Claude系列三款模型之后,在大模型廠商中排名第二,展現出強勁的技術實力。
Code Arena作為全球公認的編程大模型評測標桿,其評估體系突破傳統學術測試框架,聚焦模型在代碼生成、調試優化、架構重構等實際場景中的表現。評測機制采用動態盲測模式,通過隨機分配真實用戶需求作為考題,確保模型無法預先準備,全面檢驗其解決復雜編程問題的硬核能力。這種設計有效規避了數據泄露風險,使評測結果更具產業參考價值。
在編程能力維度,Qwen3.7-Max不僅超越了Claude-opus-4-6模型,更顯著領先于GLM-5.1、Kimi-k2.6等國內外知名模型。評測數據顯示,該模型在代碼邏輯嚴謹性、異常處理完備性等關鍵指標上表現突出,特別是在需要創造性解決方案的復雜任務中展現出獨特優勢。技術團隊透露,模型通過強化學習框架與代碼語義理解的深度融合,實現了從語法正確性到工程實用性的質變突破。
除編程專項外,Qwen3.7-Max在多模態評測領域同樣取得突破。在被譽為"AI界奧林匹克"的Design Arena評測中,該模型從全球數百個參賽模型中脫穎而出,位列綜合榜單第十名。作為基于真實用戶盲測的權威平臺,Design Arena及其圖像專項Image Arena/LMArena的評測結果,已成為衡量AI模型綜合能力的黃金標準。
行業分析師指出,Qwen3.7-Max的雙重突破標志著中國大模型技術進入全球第一梯隊。其編程能力的顯著提升,將為金融、制造、科研等領域提供更強大的智能化工具;而在多模態評測中的優異表現,則預示著該模型在內容創作、智能設計等場景具有廣闊應用前景。隨著技術持續迭代,這類具備跨領域能力的通用大模型正在重塑AI產業競爭格局。