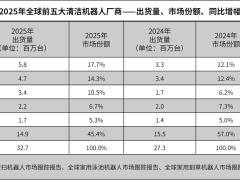
谷歌DeepMind與香港大學聯合發布了一項突破性研究,通過名為"草稿紙分塊"(Scratchpad Patching,簡稱SP)的技術,為字節級語言模型的發展開辟了新路徑。這項成果以預印本形式在arXiv平臺公開,編號為arXiv:2605.09630,標志著AI語言處理領域在計算效率與模型質量平衡方面取得重要進展。
傳統語言模型依賴分詞器將文本切割為詞語片段,但這種方法在處理罕見詞匯、外語或符號時容易出現錯誤。字節級模型直接以計算機存儲的最小單位——字節處理文本,理論上能實現跨語言、跨格式的統一處理。然而,字節序列長度是詞語序列的3-4倍,導致計算成本激增。為解決這一問題,研究人員將字節打包為"補丁"進行批量處理,但這種做法又引發了新的挑戰:模型在預測補丁內部字節時,只能依賴上一個補丁的舊信息,形成"補丁滯后"現象。
研究團隊通過類比工廠流水線解釋了這一困境:當工人每完成八個零件才能向調度室匯報進度時,調度室在指導后續生產時只能依賴上一批零件的完成情況,對當前批次的具體進展一無所知。補丁越大,這種信息延遲越嚴重,模型預測質量隨之下降。SP技術的核心突破在于,允許模型在補丁處理過程中生成臨時"草稿",這些草稿不進入最終記憶緩存,但能為后續預測提供最新信息,從而緩解信息滯后問題。
具體實現上,SP在補丁內部設置"中途匯報點",當模型預測不確定性(熵值)超過閾值時,自動觸發草稿生成。這些草稿經主干網絡處理后,僅用于當前補丁的后續預測,最終只保留補丁結束時的正式狀態。這種設計既保持了補丁模型的序列長度優勢,又通過局部信息更新提升了預測準確性。實驗表明,在固定16字節補丁的模型中,SP技術使自然語言理解任務準確率從48.0%提升至54.2%,接近不分塊字節級模型的54.1%,同時內存占用減少16倍。
在代碼生成任務中,SP的優化效果更為顯著。8字節補丁模型在MBPP測試集的通過率從24.1%提升至32.1%,16字節補丁模型則從18.2%躍升至27.5%。這種提升源于SP將計算資源精準分配到信息密集區域——實驗數據顯示,草稿觸發點主要集中在單詞邊界、專有名詞開頭等預測難點位置,而在常見詞匯中間字母處極少觸發。
研究團隊通過統一測試框架驗證了SP的普適性。在包含4000億字節訓練數據的實驗中,SP技術使四種主流補丁方法家族的質量均顯著提升,且不增加推理時的內存開銷。特別值得注意的是,SP使簡單分塊策略(如固定大小分塊)的性能追平甚至超越復雜策略(如學習型H-Net分塊),暗示計算分配方式可能比分塊邊界選擇更為關鍵。
多語言測試結果顯示,SP技術縮小了模型對非英語語言的性能差距。在FLORES-200數據集的200種語言評估中,SP優化后的補丁模型排名顯著提升,與純字節級模型的差距明顯縮小。這得益于SP不依賴特定語言分詞規則的特性,使其能公平處理所有語言。
SP技術的另一大優勢是推理靈活性。通過調整熵觸發閾值,模型可在不重新訓練的情況下動態控制草稿密度,實現質量與效率的實時平衡。實驗表明,SP模型在調整補丁大小時,質量變化比傳統模型平滑得多,展現出更強的環境適應能力。這種特性使同一模型能根據不同部署場景(如移動端或服務器端)靈活切換運行模式。
盡管取得顯著進展,研究團隊也指出SP的局限性:當前設計未減少訓練計算量,草稿更新機制較為簡單,且在多層級補丁架構中的驗證仍屬空白。未來的改進方向包括探索訓練期算力優化、設計更復雜的更新規則,以及開發對所有分塊策略都穩定的觸發機制。這項研究為字節級模型的實際應用鋪平了道路,其核心價值在于通過智能計算分配,實現了效率與質量的雙重提升。